Word Vectors in the Eighteenth Century, Episode 1: Concepts
0. Introductions
The Prelude
This is the first in a series of posts about word vectors and eighteenth-century literature. I just started playing with word vectors recently, but I’m already deeply fascinated by them-as a method, as a concept, even as a style of conceptualization. So far I’ve made a word embedding model of ECCO-TCP and have been exploring some ways that vectors can raise interesting questions for 18C studies-such as, for example, model the interactions between well-known 18C cultural-semantic debates (“Ancients” vs. “Moderns”, “Simplicity” vs. “Refinement”, “Reason” vs. “Passion”, “Invention” vs. “Judgment”, etc).
But rather than keep on randomly exploring this new cyberspace for dozens of hours while never really writing anything down, and then kinda sorta forgetting exactly what I did months later when I try to write it up as a talk-what I usually do-these days, I have the urge to actually write down what I see, to draw it out on the spot, like Darwin, or Ted Underwood, would. :) So, I thought that I would try, again, hand to my heart, to reform my hermit-like, non-blogging ways. A weird, digitized-Wordsworthian breeze comes over me: and, with the inspiring examples of DH bloggers everywhere before me, I set out!
The Plan
I begin by pointing to why vector space semantics has become so interesting recently: the ability of new models to represent and predict, mathematically, semantic relationships between words as complex as analogy: Man is to Woman as King is to what?, you ask; Queen, the model replies. The next section re-approaches this same topic in an eighteenth-century context, close-reading word vectors by close-reading the analogy, Riches are to Virtue as Learning is to Genius, lying at the heart of Edward Young’s influential arguments, in 1759, for original composition over neo-classical imitation. In the last section, I indulge sublunary thoughts on how modeling conceptual relationships through mathematical operations raises interesting questions about the status of concepts themselves, both those of the eighteenth-century and our own.
In the next post, I’ll go more into the methods and maths behind vector space semantics: a public self-struggling to explain it to myself. And then in the posts following that, I’d like to narrate some of my recent explorations distant-reading a strange and multidimensional eighteenth century.
Previous work
But, before I go any further I should note the excellent DH work already out there on word vectors. Ben Schmidt has an incredible post on word vectors and DH, “Vector Space Models for the Digital Humanities” (25 Oct 2015). He has also released an R package for computing word vectors and instructions on how to use it. I learned a lot about vector space semantics from Schmidt and would refer everyone to his more capable introduction.
I’ve also been very much inspired by Michael Gavin’s post, “The Arithmetic of Concepts: a response to Peter de Bolla” (19 Sep 2015). Gavin beautifully articulates the conceptuality of word vectors and how they can be leveraged for a cultural-conceptual analysis. Douglas Duhaime’s post, “Clustering Semantic Vectors with Python” (12 Sep 2015), demonstrates how to find semantic clusters within word vectors, which seems to me a novel approach to generating semantic fields. And Lynn Cherney has used word vectors to hilarious and revealing effect with an Oulipo-style deformation of Pride and Prejudice.
1. Why all the hype?
The word vectors I’ve been talking about are more accurately a particular kind of word vector, one inside a particular kind of model called a word embedding model. Even though this kind of model has a longer history, there’s apparently been a craze about this kind of vector space semantics for only the last few years-begun, in part, by Google, when researchers there unveiled newly efficient algorithms in 2013 for computing this kind of model, packaged in software they released called word2vec.
The hype, however, really arises from the shocking complexity and accuracy of the semantic relationships between words that word vectors within word embedding models are able to express. The canonical example is analogy. Word vectors are able to express and predict, mathematically, that “man” is to “woman” as “king” is to “queen”; or that “London” is to “England” as “Edinburgh” is to “Scotland”. These analogical relationships can be expressed mathematically in terms of word vectors: V(woman) - V(man) + V(king) ≈ V(queen). Start with the vector for “woman”; then subtract from it the vector for “man”, leaving behind only what is unique about V(woman) as distinct from V(man); then, add this distinct difference to V(king). You end up with a brand new vector position: V(woman-man+king). Which word vector, out of thousands of other words, is closest to V(woman-man+king)? In most word embedding models: V(queen).
Although these are toy examples, the possibilities for DH (as well as 18C studies) of an expressive model of, say, 18C semantic relationships, remain vast, and have only just begun to be explored. These possibilities seem especially fruitful for a conceptual analysis of culture-outlined, more recently, by Peter de Bolla in Architecture of Concepts and Michael Gavin’s vector-based essay in response; but of course also by the long tradition of intellectual history, from Koselleck and Begriffsgeschichte, to Quentin Skinner and the Cambridge school, and to perhaps its most eminent practitioner in our own discipline, Raymond Williams.
2. A close reading of word vectors in the 18C
As a brief example of word vectors in action in the 18C, let’s think back to the argument made by one of the most outspoken proponents of “original composition” over imitation of the ancients, Edward Young, in Conjectures on Original Composition: In a Letter to the Author of Sir Charles Grandison (1759). Young makes his ingenious argument by interweaving and correlating the literary-conceptual opposition between original and imitative composition with several other conceptual oppositions:
| Type of opposition | Associated with original composition | Associated with imitative composition |
|---|---|---|
| Attributes of a Poet/Author | Genius | Learning |
| Forms of social organization | Organic growth | Mechanistic commerce |
| Forms of social value | Virtue | Riches |
_Table 1. Table of conceptual analogies leveraged by Edward Young to argue for original over imitative composition in _Conjectures on Original Composition (1759).
For instance, to take the last of these, Young argues that, just as Virtue does not need Riches but that Riches are wanted when there is no Virtue, so Genius does not need Learning but Learning is wanted when there is no Genius. Both Genius and original composition are thereby ethically transvalued through their analogical relationship to the ethics of Virtue. Through analogy, Young also locates a conceptual center to these intersecting oppositions. The individualist, immanent claim to value shared by Virtue, Genius, and original composition becomes visible when analogically contrasted with the more socially-embedded and class-based forms of value shared by wealth (“Riches”) and academic study (“Learning”). “With regard to the Moral world, Conscience, with regard to the Intellectual, Genius, is that God within,” Young writes, underscoring this concept of ethical immanence arising from and through this network of analogical relationships.
Word embedding models can help us reconstruct and explore this historically-situated network of conceptual relationships. A word embedding model trained on ECCO-TCP can answer not only the more trivial analogies of man is to woman as king is to…? (“queen”), and London is to England as Edinburgh is to…? (“Scotland”). We can also explore the very analogy Young proposed, and ask the model: Riches are to Virtue as Learning is to…?
In [3]: analogy(model, 'riches', 'virtue', 'learning')
Out[3]:
[(u'morality', 1.0672287940979004),
(u'piety', 1.0626451969146729),
(u'science', 1.0292117595672607),
(u'philosophy', 1.0257463455200195),
(u'prudence', 1.0140740871429443),
(u'genius', 0.9834112524986267), # <-- 6th closest term
(u'wisdom', 0.9778728485107422),
(u'morals', 0.9766285419464111),
(u'modesty', 0.9748671650886536),
(u'humanity', 0.972758948802948)]Admittedly, I really don’t know anything yet about measures of statistical significance in analogy testing-but, to me, the fact that, out of thousands of possibilities, the 6th closest word vector to the composite, analogical vector V(Virtue-Riches+Learning) is, as Young argued, V(Genius), is remarkable.
In other words, start with the semantic profile of “Virtue” expressed in V(Virtue); then, subtract from it the semantic profile of “Riches” expressed in V(Riches). The result is that the semantic aspects that they shared are removed, and only the aspects on which they differed left behind. This specific semantic contrast is captured in a new composite vector: V(Virtue-Riches). In natural language, V(Virtue-Riches) means Virtue as given by its distinctness from Riches. This new vector is not a word vector, but rather a particular relationship between word vectors-namely, a relationship of conceptual contrast, modeled as the relationship of mathematical subtraction.
In this way, V(Virtue-Riches) is an independent concept from its components. Unlike its components, V(Virtue) and V(Riches), which, as words, have direct expression in language, V(Virtue-Riches) is instead a relationship between those expressions, emergent through their contrast. There is, then, a sense in which V(Virtue-Riches) has no direct expression in language; and therefore also a sense in which we might think of it as an artificial, even virtual, concept. And yet in spite of its ontological fragility-or, more interestingly, through it-V(Virtue-Riches) gives formal expression to a concept that couldn’t be more real and natural to the 18C: the concept of Virtue as contrasted with Riches.
One potential interpretation of this autonomous concept, V(Virtue-Riches), would be the one outlined by Young above. V(Virtue-Riches) might express, at least in part, the conceptual contrast that seems to lie at the intersection of Young’s correlated analogies: the contrast between ethically immanent and comparatively individualist forms of value (“Virtue”, “Genius”, original composition) on the one hand, and more socially-embedded and class-based forms of value (“Riches”, “Learning”, imitation of received classical models) on the other. This interwoven interpretation is strengthened by the fact that, in the model, adding the contrast between “Virtue” and “Riches”-expressed as V(Virtue-Riches)-to the concept of Learning expressed in V(Learning), produces a new vector V(Virtue-Riches+Learning) to which the sixth closest word vector happens to be V(Genius).
This process has in turn produced, arguably, a new concept. What does V(Virtue-Riches_+Learning_) mean? If we take the interpretation above on premise for a second, and accept that V(Virtue-Riches) expresses a conceptual contrast pointing toward immanent/individualist value (“the God within”) and away from social/class-based value, then we can translate this question as: What does it mean to move along this conceptual axis, but this time starting at Learning? The model articulates this question as a new, analogical concept V(Virtue-Riches+Learning)-that is, Riches are to Virtue as Learning is to [X]? Apparently, the vector space model thinks [X] must be conceptually similar to the concepts of “morality” and “piety”; “science” and “philosophy”; and “prudence”, “genius”, and “wisdom.”
I don’t want to over-interpret the results: this is only meant to be a provocative example, and I think any further argument would have to be backed up by other methods, looking at passages, etc. But even at a first glance, it seems clear how a move toward immanent value, from Learning, would be consistent with almost every term on this list. Even the apparent outliers, Science and Philosophy, have-at least to my own, my all-too-human vector space semantics, my brain and my memory-softer resonances than Learning in terms of an Cambridge/Oxford academic profile; and, conversely, stronger ethical resonances, being closer to the ethical orbit of Reason.
3. Vector space semantics and the concept of the concept
In any case, even without accepting the previous section’s interpretation or even giving credence to its particular analogy, I think it suggests that word vectors might also be productive theoretically, in addition to being a convenient methodology for “capturing” semantic relationships from a corpus of 18C texts. Word vectors raise epistemological questions about the status of concepts themselves-both our own concepts and those of the 18C. As Gavin asks in “The Arithmetic of Concepts”, what does it mean for concepts to enter into arithmetical operations with each other?
In other words, vector space semantics allows us to ask not only what the concept of “Virtue” or “Riches” is-V(Virtue)? V(Riches)?-but also what a third concept is, one that results from a conceptual-arithmetic operation like subtraction: V(Virtue-Riches)? V(Virtue-Riches) gives mathematical expression to a concept already inherently subtractive: the concept of Virtue, as contrasted with Riches. This third concept is mathematically, and conceptually, its own entity. It is also arguably a mathematical-formal expression of the same concept that Young articulated through his contrastive operation of analogy-which seems fair to call a very eighteenth-century, ethically-overdetermined form of conceptual operation. Riches are to Virtue as Learning is to Genius.
The mathematical concepts within vector space semantics therefore do more than represent the semantic relationships within 18C discourse; the very mathematical operations of which they consist also make visible the mathematical operationality always already present in 18C discourse. Particular combinations of vector operations make visible the particular combinations of conceptual operations active in the period. These conceptual operations are thereby revealed as historically-situated, while at the same time modeled as existing independently, mathematically even, as an abstraction-as form does for Caroline Levine. In the eighteenth century, with a print culture still dominated by sermons and religious and political tracts, many of which written in bitter rejoinder to each other, and for which contrast and analogy served as dialectical weapons, it’s conceivable that distinctive variants of conceptual operations like contrast and analogy were not only present and active in the discourse, but may have themselves evolved out of the forces within and behind the rapidly growing publication industry itself.
As an example of what a historically-situated form of conceptual operation might look like, we could perhaps look back to Reviel Netz’s The Shaping of Deduction in Greek Mathematics: A Study in Cognitive History (1999), in which he diagrams the argumentative logic behind different geometric proofs by Euclid, Aristotle, and others:
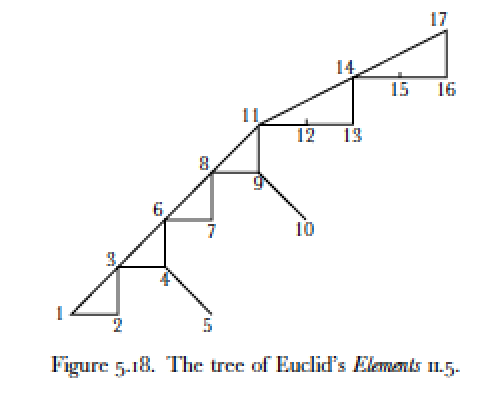
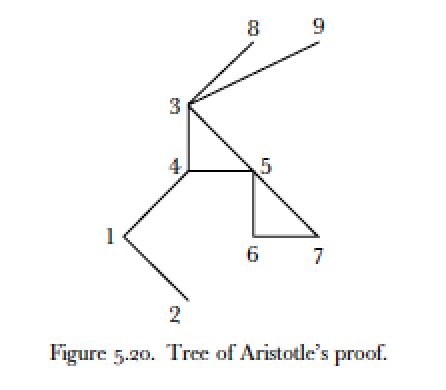
Figure 1: Diagrams of the structure of one of Euclid’s and Aristotle’s proofs. Triangles result from a “therefore” conceptual operation; the disconnected lines, from a “because” operation (203ff.)
Retrospectively, Netz’s diagrams would seem to be one possible response to Peter de Bolla’s recent calls for a conceptual turn in literary study, re-motivated by a renewed emphasis on what he calls conceptual architecture:
That internal structure-call it the disposition of its elements-coupled to its connections within and across networks of associated and differentiated concepts is what I call the “architecture” of a concept.
As Gavin persuasively argues in “The Arithmetic of Concepts: a response to Peter de Bolla”, vector space models might be another possible, and powerful, response to such a call. At the very least, they seem to raise fascinating questions for conceptual-cultural history. And as De Bolla laments in Architecture of Concepts, concepts are currently “undertheorized. There is no widely applied ‘theory of the concept’, no specific description of the kinds or types of conceptual form.” If so, then the fields are open: what can word vectors do to help us explore such forms in action in the 18C?
Stay tuned for the next episode of “Word Vectors in the Eighteenth Century”…
-1. Appendix
The model I’m using was made with gensim, a Python implementation of word2vec’s neural-network-based algorithms for generating a word embedding model. The model was trained on skip-grams of 5 words from the entire corpus, using 100 dimensions for the neural network. With 4 workers it took a few hours to train.
Since ECCO-TCP is freely available online, I’ve uploaded the word2vec model I’ve trained on ECCO-TCP. To use this model, download it, unzip it, and then either load it using the original word2vec software, Ben Schmidt’s R package, gensim, or another implementation. Here’s the code for gensim:
import gensim
model = gensim.models.Word2Vec.load_word2vec_format('word2vec.ECCO-TCP.txt')
# Man is to Woman as King is to ___?
print model.most_similar(['woman','king'], ['man'])
tags indicated prose. Prose is responsible for an even larger extent of the words: 66%, to Drama’s 23%, and Poetry’s 11%.